Aujourd’hui on va parler de sources de données et data quality.
Comme je le disais il y a quelques semaines, je me base sur les données de l’ATP tour que je récupère grâce au travail incroyable de Jeff Sackmann de Tennis Abstract.
Une des sources de données à dispo est : le top 1000 par semaine depuis 1973
Méthode : stockage des données dans GCP, transformation dans BigQuery et visualisation dans Looker Studio.
C’est en faisant l’analyse la semaine dernière des progressions les plus importante sur le circuit que je me suis rendu compte d’erreurs et de trous dans la base de l’ATP tour ! 😱
On voit :
➡ Des joueurs qui ont deux classements sur une même semaine.
➡ Des joueurs qui n’ont pas de classement certaines semaines.
Sur ce deuxième point, on peut prendre comme exemple : Ralf Pedersen pour lequel on a un classement en 1983 puis plus rien et un nouveau en 2006..
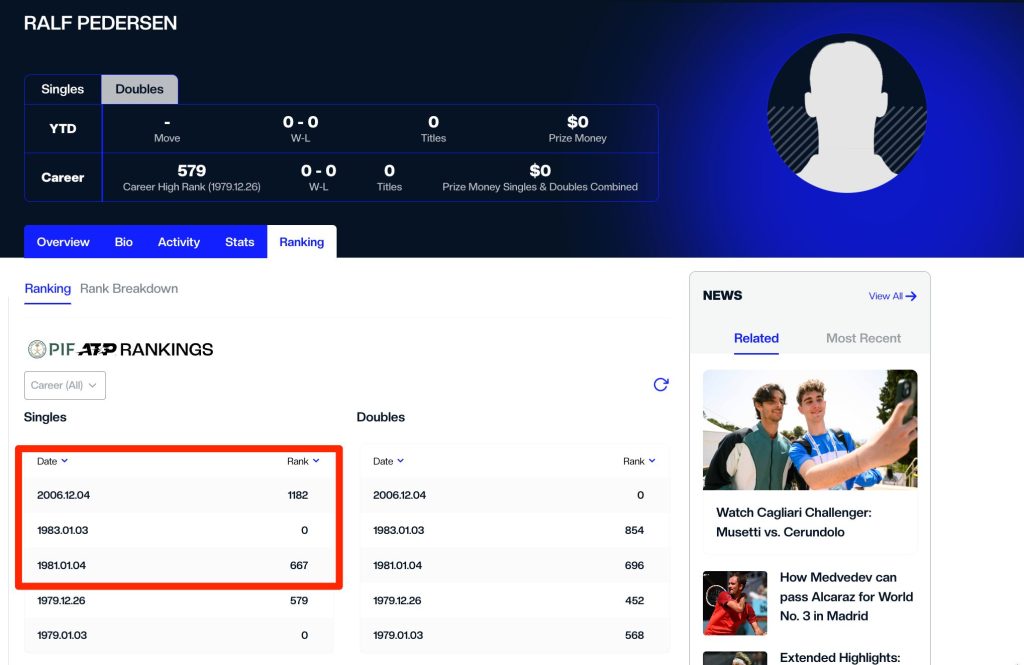
Alors deux hypothèses :
1️⃣ On assiste à un retour incroyable de Ralf mais à mon avis peu probable et on aurait quand même sont classement par semaine
2️⃣ il y a quelques incohérences dans la base et même sur le site de l’ATP tour.
J’ai donc calculé la différence de jour entre les deux semaines de classements entre les joueurs pour mesurer les données « perdues » sur le site de l’ATP tour et intégrer ce paramètre pour mes analyses.
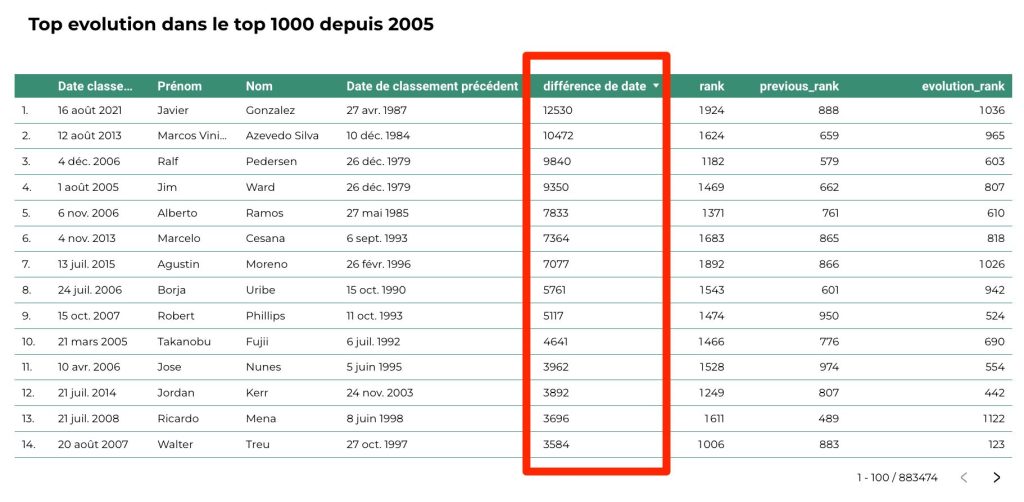
Conclusion de ce post :
Cela montre bien l’importance de ce sujet de Data Quality sur lequel nous accompagnons de nombreux clients chez Unnest – Cabinet de conseil Data Tech. Sujet qui peut être assez chronophage, mais qui reste essentiel !
Et un grand merci pour l’aide d’Eva Despesse qui chaque semaine me fait découvrir BigQuery et m’aide dans ce projet ! 🙏
Prochaine étape :
👉 Mettre en place une méthodologie pour systématiser cette vérification de la qualité de la donnée
👉 Tester Dataplex, l’outil Google Cloud pour gérer la gouvernance des données