On va parler ici d’exploration de données, d’analyse en composante principal et essayer d’utiliser cette méthode pour catégoriser les masters 1000 et rapprocher les tournois présentant des similarités.
Data ingénieur de passage, je vous prie de rester indulgent et suis preneur de retours pour faire évoluer cette analyse 😊
L’analyse en composante principale c’est quoi ?
L’analyse en composantes principales aussi appelé ACP est une méthode les plus connus en analyse de données multivariées qui est utilisée pour explorer des ensembles de données multidimensionnelles avec des variables quantitatives.
Alors concrètement qu’est ce que ça veut dire ?
Présentation détaillée de l’ACP
L’ACP projette les observations d’un espace à p dimensions (avec p variables) vers un espace à k dimensions (où k < p), tout en conservant le maximum d’information, mesurée par la variance totale des données. Les nouvelles dimensions, appelées axes ou facteurs, permettent de réduire la complexité des données. Si les premiers axes expliquent une part significative de la variance, les observations peuvent être représentées graphiquement en 2 ou 3 dimensions, facilitant ainsi leur interprétation.
En tant que méthode d’exploration de données, l’ACP permet d’extraire des informations de grands ensembles de données. Elle est utilisée pour :
- Étudier et visualiser les corrélations entre variables, réduisant potentiellement le nombre de variables à mesurer.
- Obtenir des facteurs non corrélés, qui sont des combinaisons linéaires des variables initiales, utilisables dans des méthodes de modélisation telles que la régression linéaire, logistique ou l’analyse discriminante.
- Visualiser les observations dans un espace réduit pour identifier des groupes homogènes ou des observations atypiques.
Présentation simplifiée de l’ACP
En gros, l’ACP prend des données avec beaucoup de variables et les réduit à quelques-unes tout en conservant l’essentiel de l’information. Imagine que vous ayez un tableau avec beaucoup de colonnes (variables) ; l’ACP les transforme en un tableau avec moins de colonnes, mais qui raconte presque la même histoire.
Analyse en composante principale appliquée aux tournois ATP
Préparation de l’analyse
Objectif: classifier les tournois ATP présentant des statistiques similaires
Use case potentiel pour un joueur : identifier les tournois à privilégier dans sa programmation. Si un joueur performance souvent dans un tournoi, il pourra ainsi trouver les tournois équivalents sur lesquels il peut espérer performer.
Données à disposition : la moyenne de plusieurs indicateurs (voir ci-après) par tournois de 2010 à 2023.
| Champs | Détail | Exemple / Type |
| tourney_name | Nom du tournoi | Wimbledon |
| game_nb | Nombre de jeux par match | INTEGER |
| set_nb | Nombre de set par match | INTEGER |
| minutes | Temps en minute d’un match | INTEGER |
| ace | Nombre d’ace par match | INTEGER |
| df | INTEGER | |
| svpt | INTEGER | |
| first_in | Ratio de premier service par match | INTEGER |
| first_won | Ratio de point marqué après un premier service | INTEGER |
| second_won | Ratio de point marqué après un second service | INTEGER |
| sv_gms | INTEGER | |
| bp_saved | Nombre de balles de break sauvées | INTEGER |
| bp_faced | Nombre de balles de break jouées | INTEGER |
Calcul et transformation de la donnée
Je vous passe ici les formules mathématiques que je n’ai pas absolument pas pris le temps de comprendre. J’ai utilisé quelques tutos + chatGTP pour faire cette analyse directement en python.
Mais pour simplifier les différentes étapes :
- Standardisation des données
- Calcul de la matrice de covariance (ou de corrélation) : pour comprendre comment les variables varient ensemble.
- Calcul des valeurs propres et des vecteurs propres : pour identifier les directions dans lesquelles les données varient le plus.
- Formation et selection des composantes principales
- Visualisation dans un graphique
- Interprétation des résultats
Analyse des tournois ATP
j’ai fait dans un premier temps une analyse avec tous les tournois ATP :
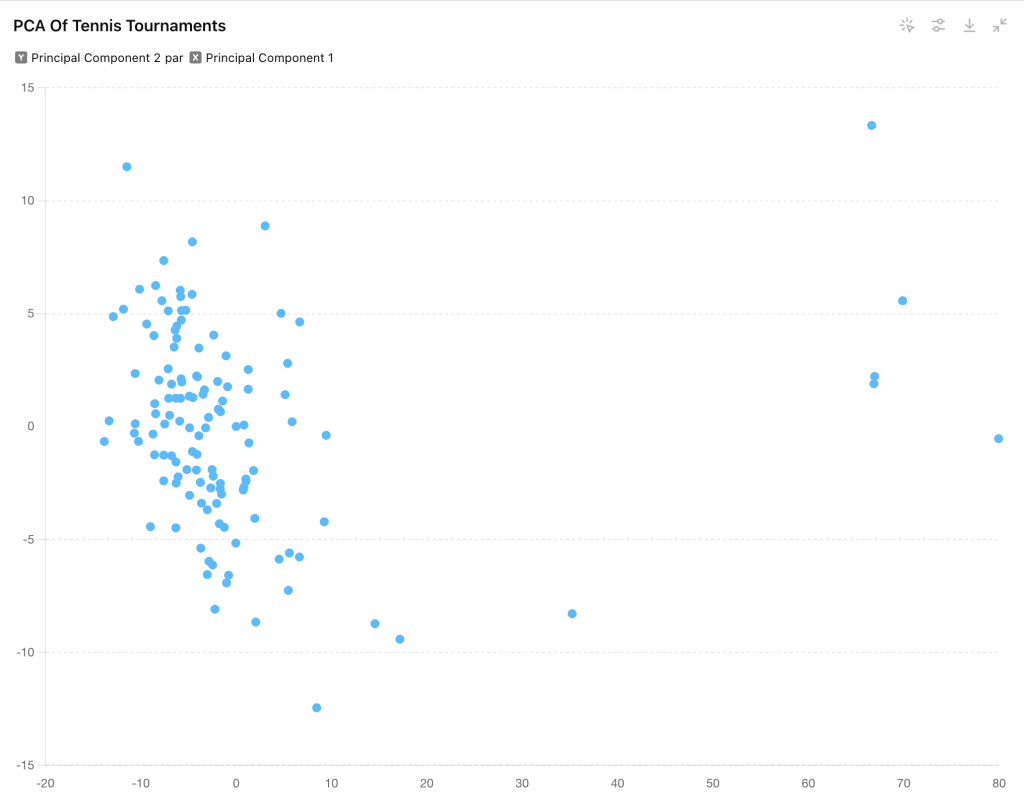
Et avec le nom des tournois
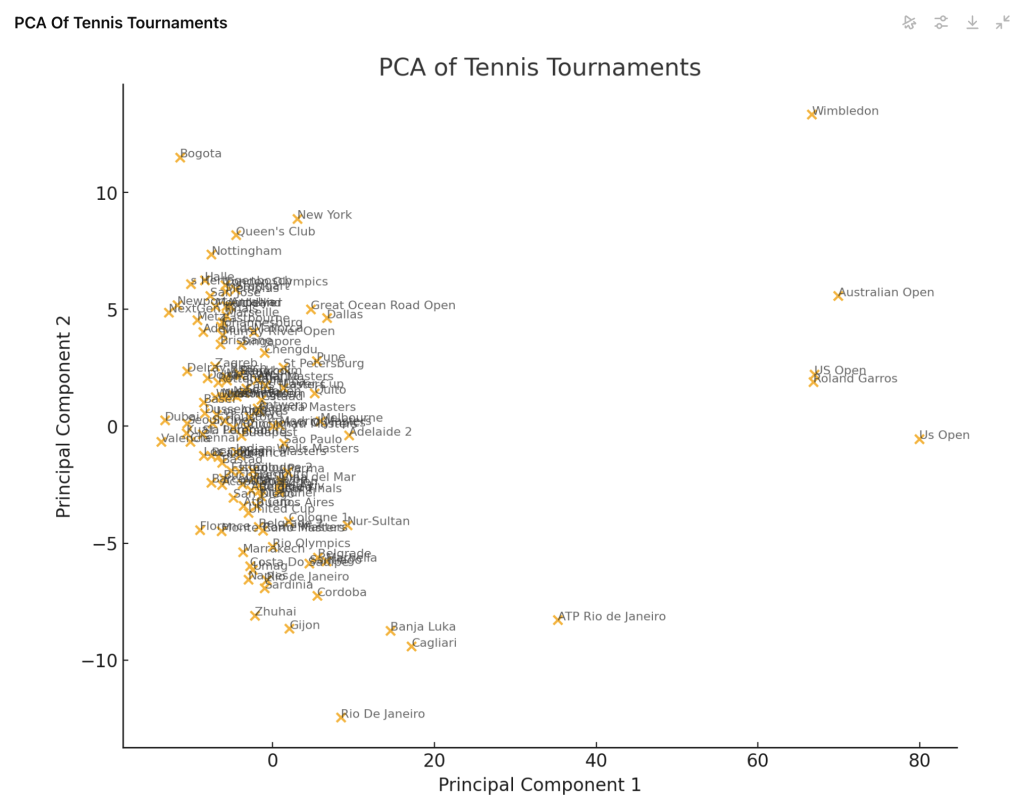
| Pour lire ce graphique, voici quelques points clés à comprendre : 1 – Axes des composantes principales : Composante principale 1 (PC1) : Représente l’axe horizontal. C’est la direction qui explique le plus de variance dans les données. Composante principale 2 (PC2) : Représente l’axe vertical. C’est la direction qui explique la deuxième plus grande part de la variance, orthogonale à la première composante. 2 – Position des points : Chaque point représente un tournoi de tennis. La position d’un point sur le graphique est déterminée par ses scores sur les deux premières composantes principales (PC1 et PC2). Les tournois qui sont proches les uns des autres dans l’espace des composantes principales ont des caractéristiques similaires selon les variables initiales (nombre moyen de jeux, nombre moyen de sets, minutes moyennes, etc.). 3 – Interprétation des distances : Plus deux points sont proches, plus les tournois correspondants sont similaires. Si un point est éloigné des autres, cela indique que le tournoi a des caractéristiques distinctes par rapport aux autres tournois. 4 – Signification des axes : Les axes sont des combinaisons linéaires des variables originales. Pour interpréter ces axes en détail, il faudrait regarder les coefficients de ces combinaisons, ce qui peut indiquer quelles variables ont le plus contribué à chaque composante principale. |
On voit bien les grand Chelem en haut à droite du graphique : cela s’explique par le fait que ce sont les seuls tournois qui se jouent en 3 sets gagnants ce qui impact fortement les données.
Pour plus de clareté, j’ai filtré uniquement sur les 9 masters 1000, et on voit des choses très intéressantes :
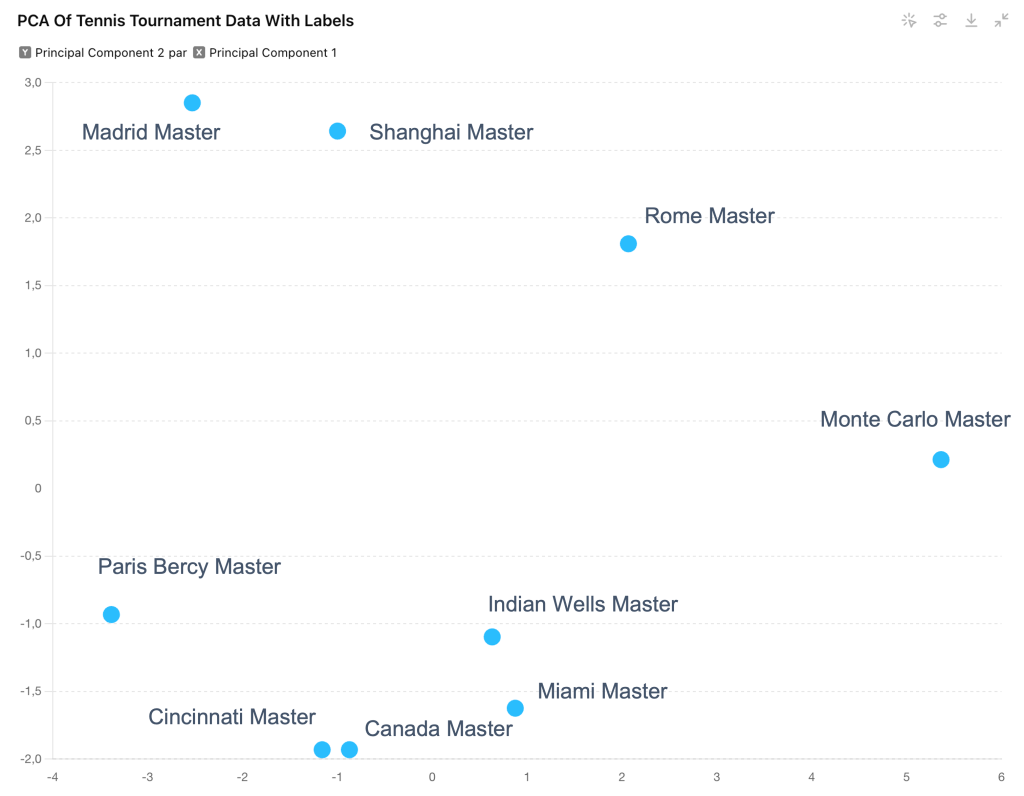
On remarque que les tournois de Cincinnati et le Master du Canada (entre Toronto et Montréal) sont très proche par exemple.
Conclusion et next step
Le type d’analyse est plutôt très intéressant mais peut être pas encore assez concret, je vais creuser ce sujet dans un autre article pour rentrer dans le détail de ce qui rapproche un tournoi avec un autre et croiser ces informations avec les derniers résultats.